Releasing GPT-JT powered by open-source AI
A fork of GPT-J-6B, fine-tuned on 3.53 billion tokens, that outperforms most 100B+ parameter models at classification. GPT-JT was trained with a new decentralized algorithm with 1Gbps interconnect, in contrast with typical 100Gbps-1.6Tbps data center networks.
Here at Together, we have been working to bring the world’s computation together to support the open models ecosystem. And we have been developing decentralized training algorithms to take advantage of heterogeneous GPU hardware connected over slow (1Gbps) internet links. Over the past few weeks, we built GPT-JT (6B), a model that integrates several recently published open techniques and datasets and was trained with our decentralized approach on the Together Research Computer.

GPT-JT (6B) is a variant forked off GPT-J (6B), and performs exceptionally well on text classification and other tasks. On classification benchmarks such as RAFT, it comes close to state-of-the-art models that are much larger (e.g., InstructGPT davinci v2)! GPT-JT is now publicly available as open source: togethercomputer/GPT-JT-6B-v1, along with a live demo on the GPT-JT HuggingFace space.
Notably, and somewhat more importantly than the model itself, which represents a first step, we want to highlight the strength of open-source AI, where community projects can be improved incrementally and contributed back into open-source, resulting in public goods, and a value chain that everyone can benefit from.
GPT-JT was possible because of work published by several collectives, organizations and researchers:
- EleutherAI who created open models (e.g., GPT-J-6B, GPT-NeoX) and datasets (e.g., the Pile) are the basis of GPT-JT. EleutherAI’s work has become the cornerstone of today’s foundation model research.
- Google Research who published UL2 and Chain-of-Thought (CoT) techniques.
- We use Natural-Instructions (NI) dataset, a collection of over 1.6K tasks and their natural language definitions/instructions. This is an amazing community effort driven by researchers from many universities and companies such as AllenAI.
- We also use BigScience’s Public Pool of Prompts (P3) dataset, a collection of prompted English datasets covering 55 tasks.
- We base our main evaluation on RAFT, a fantastic dataset curated by researchers at Ought (and others) for text classification.
- We use HELM by Stanford CRFM, a project for Holistic Evaluation of Language Models, to evaluate and understand the quality of the model in a wider context.
- Our decentralized algorithm is inspired by lo-fi and ProxSkip by Ludwig Schmidt, Mitchell Wortsman, Peter Richtárik, and others.
We host and distribute the model through HuggingFace, which is the hub for the open-source AI ecosystem.
The power of openness
Our journey building GPT-JT starts from the open checkpoint of GPT-J-6B. We incorporated the collection of techniques mentioned above and continued pre-train given the GPT-J-6B model. We first conduct training for 2.62 billion tokens using the UL2 loss, followed by 0.92 billion tokens of a loss that is a mixture of three components: 5% of COT, 20% of P3, 20% of NI, and along with 55% the standard language modeling loss on the Pile. The result is GPT-JT.
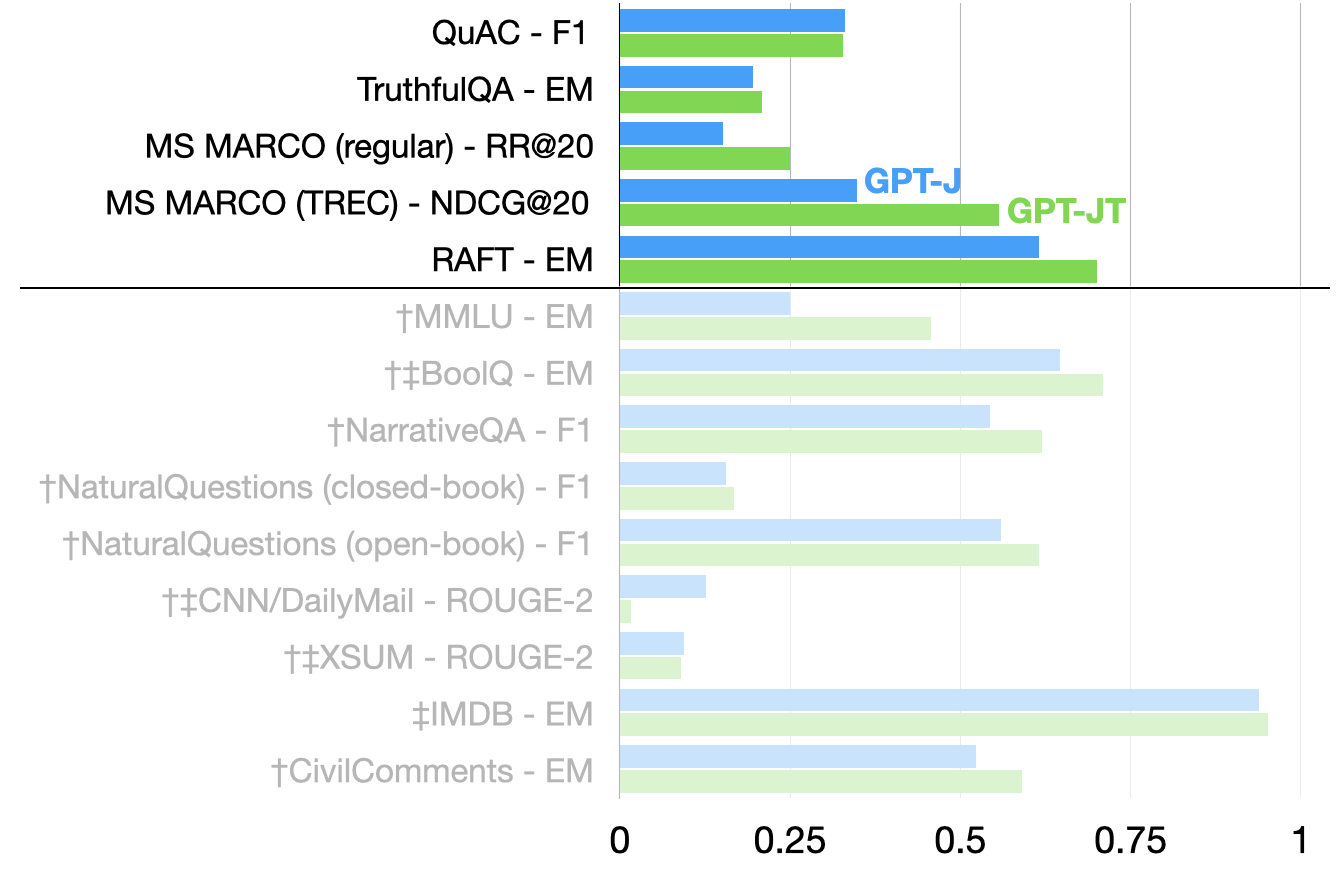
We evaluate GPT-JT on the RAFT dataset, which consists of a diverse collection of text classification tasks. RAFT provides representative workloads of many real-world use cases and therefore we chose to base our evaluation on it. We follow the protocol used in HELM, which contains the evaluation results for many open and closed models. As illustrated in Figure 1, GPT-JT significantly improves the RAFT score over the original GPT-J. In fact, it outperforms most other models, some with even 100B+ parameters. GPT-JT also provides improvements over many other tasks, including the tasks that are in HELM’s core scenarios (See Figure 3). If you have suggestions and ideas on how to improve the model further please reach out as we’d love to work together, and introduce new ideas for the next iteration of training.
Decentralization-friendly training
GPT-JT is trained with a new decentralized algorithm: Instead of having all machines connected via fast data center networks, we only have slow connections of up to 1Gbps. This causes problems for traditional distributed learning algorithms—for GPT-JT, we used 4-way data parallellism, which would lead to the communication of 633 TB data per machine during the whole training process! Under a 1Gbps network, this would amount to 1440 hours just for communication. Instead, we use an optimizer that is based on our previous work (for example, see one such example at the upcoming NeurIPS) and a strategy based on local training which randomly skips global communications. GPT-JT only requires 12.7 TB of total communication per machine for all 3.53 billion tokens, adding only a <50% overhead to the end-to-end training time under 1Gbps networks.
GPT-JT is just the beginning. We believe we can make our field more accessible to researchers and practitioners via decentralized computing. We thank everyone whose hard work makes this possible!

- Lower
Cost20% - faster
training4x - network
compression117x
article